
Git has been a central part of the DevOps story. Our continuous integration systems run builds, produce artifacts, execute tests, and ultimately deploy systems defined as code in our git repositories. More recently, GitOps has extended the reach of git towards a better understanding of our kubernetes workloads. But does that come with hidden challenges?
In this post I’ll take a look at the benefits of everything-as-code before considering some of the gaps that remain in how we describe and understand our process. Capturing static definitions of build, test, deploy, etc. are useful to us, but how do we gain an understanding of how our code behaves when it’s actually running? Can we get a handle on how our environments and pipelines are really changing?
Git blaming for broken code can be super frustrating. Diff your environment history to quickly find the change you need with the Kosli CLI
Try for freeWhy use version control at all?
I’m old enough to remember the rush of joy setting up jobs in Hudson (the precursor to Jenkins). Hudson had a slick user interface where you could create new jobs directly in your browser, and you could get something up and running in no time. It felt like a massive leap forward from cruise control, where we would use xml files on the server to define jobs.
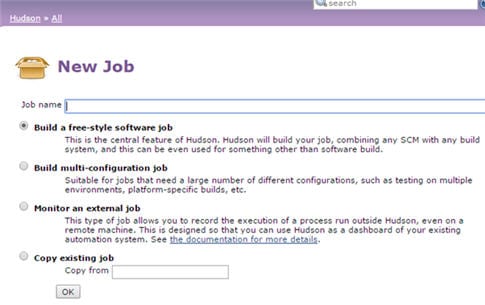
In the job configuration you had a text box where you could enter your build script. If you needed to add extra steps, or change your build options, you’d just edit the job settings.
Along the way, we learned that defining this process in a build script and adding it to version control would ensure that developers and CI were building in the same way. Or as Coding Horror put it, the f5 key is not a build process. This simple approach brought many advantages:
- It ensures everyone on the team uses the same process
- There’s only one place to update if you change your build
- The version history of the build is in sync with code
- It’s easier to get new team members started
DevOps: Automating the value stream in git
Before long, the worlds of agile software development, continuous integration and value stream thinking merged into a new movement: DevOps.

This extended the scope of our continuous integration and DevOps practices into testing, releasing, deployment, and infrastructure changes. And as we automated these steps, we applied the same pattern of defining them “as-code” and storing them in git.
This led to faster and more frequent deployments, and higher levels of overall change.
The benefits of “everything-as-code”
By defining the whole value stream as code and storing it in version control you get a lot of advantages:
- Better transparency: enables sharing, reviewing and auditing in a familiar technology
- Code tools and workflows: enabling branching/pull-request based approaches to integrate change
- Better Quality: allows you to add linters, checkers and static analysis in the automation processes, and enforces consistency of changes
- Immutability: helps minimize configuration drift
- Centralization: can help reduce “configuration sprawl”: the configuration of processes spread over multiple unconnected systems
The challenges of “everything-as-code”
With all these advantages, what’s not to like? As a developer, you can get your changes out faster than ever, with better quality.
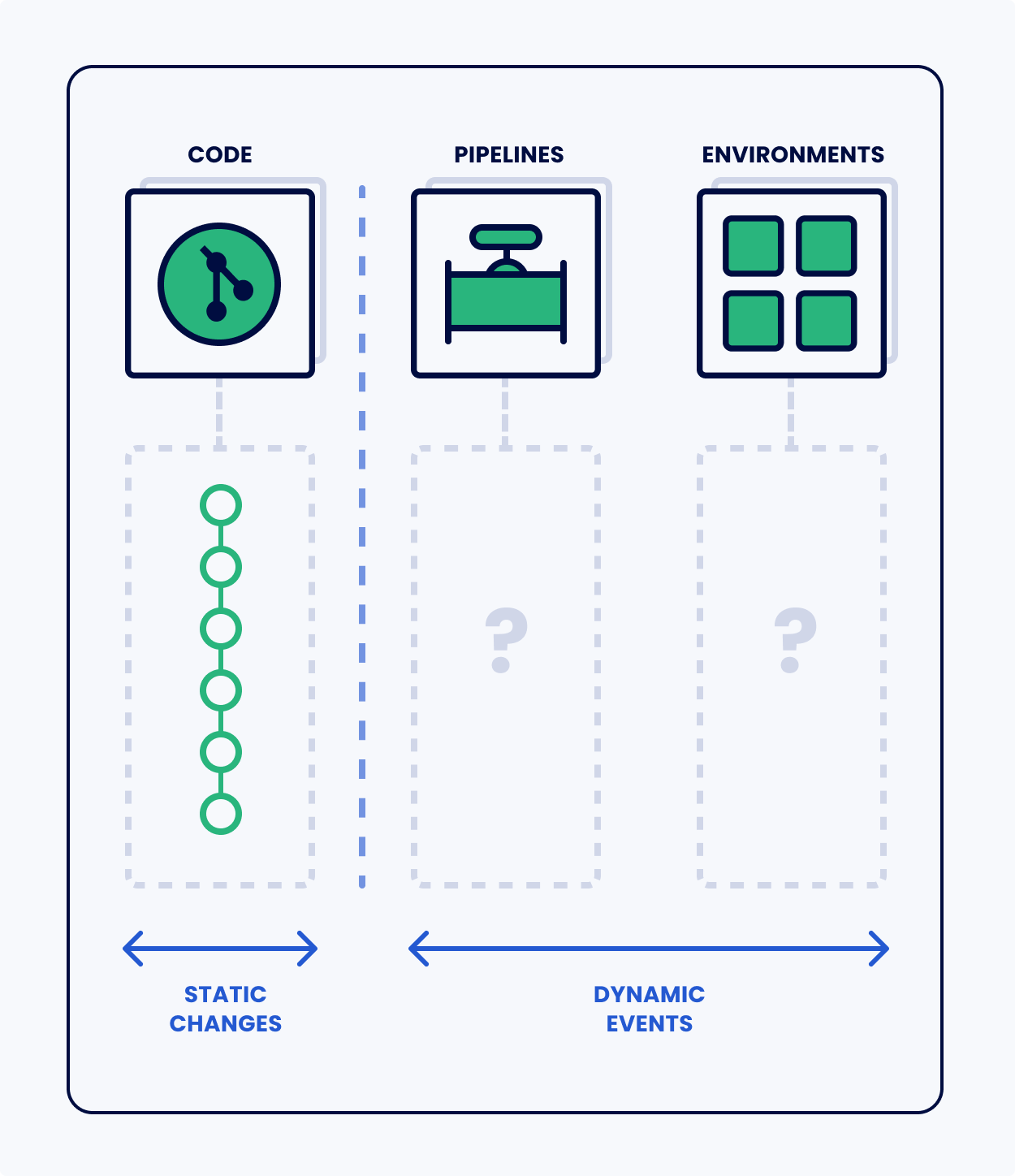
But there is something missing in this picture: the dynamic view.
Code is a static definition of a process. But this code runs somewhere. At some time. Based on some trigger. For example:
| Static definition | Dynamic execution |
|---|---|
| Build Script | Compilation/Packaging |
| Test suite | Test runs |
| Deployment script | Deployments |
| Docker file | Docker image builds |
| Infrastructure model | Infrastructure changes |
It’s like we’re defining everything as nouns (things) without making room for the verbs (actions). Without a record of dynamic processes in our DevOps we are missing key information about what is going on:
- We don’t know when any of these processes run
- We don’t have a record of their results (we don’t know when they fail)
- We don’t have a record of their products (binary artifacts, test results, model changes)
- The process steps are unconnected from each other (and the code)
So, without a record of the changes (verbs) connected to the definitions (nouns), it’s
much harder to discover the cause of bad situations like broken environments.
The SRE Book states that “70% of outages are due to changes in a live system.” If change is good, but change causes errors, perhaps we could record the actual changes?
Is GitOps the answer?
Intuitively, GitOps seems like the answer. It allows us to control our runtimes by specifying desired changes as code (or data more correctly) and store it in version control. But there is a gap between desires and actuals. And this is often where the errors creep in.
GitOps doesn’t capture the moments if changes are applied. It can’t tell users when their code has been deployed. And it won’t catch any manual changes that have crept in either. We must also remember that not everyone is using Kubernetes. There are other runtime environments (ECS, Lambda, S3, etc) with the same knowledge gaps that require the same solution.
Conclusion
Git offers a pretty good answer to any DevOps question. More and more of our value stream is recorded in git “as-code” and interpreted by CI systems, DevOps tools, and deployment engines. And I’m pretty sure none of us would want to return to the days before we were defining everything as code any more than we’d want to return to a world without version control.
If anything, the success of everything as code has shown us where the gaps still remain. Git has the static world of recipes taken care of, but we need a way of capturing dynamic changes if we are going to really understand what’s happening in our pipelines and, ultimately, deployed to our environments.




