Can you create an audit trail for what your AI agent actually did, and enforce rules about what it was allowed to do? Here’s what I found after spending a session wiring the two tools together.
The Problem Nobody Has Solved Yet
AI coding assistants have crossed a threshold. Developers aren’t just using them to autocomplete a line or explain a stack trace. They’re delegating whole features, refactors, and infrastructure changes to agents that run dozens of tool calls autonomously before you even see the diff.
That’s genuinely useful. It’s also genuinely uncomfortable if you’re the person responsible for what ships.
The discomfort isn’t vague. It’s specific:
- Attribution: Which parts of this commit did the agent write, and which did a human review?
- Intent: What was the developer trying to accomplish when they started this session?
- Permissions: Was the agent allowed to do what the transcript shows it did?
- Evidence: Can I prove any of this to a regulator, an auditor, or a postmortem investigation?
Most teams currently answer these questions with “trust the developer”, which is fine until it isn’t. Regulated industries (finance, healthcare, critical infrastructure) can’t absorb that answer. And even unregulated teams are discovering that “the AI wrote it” is a real gap in their incident response playbooks.
I spent a session exploring whether Entire and Kosli could be combined to give a concrete, verifiable answer to at least some of these questions.
Two Platforms, One Problem
Entire: Checkpoints for AI Coding Sessions
Entire was founded by Thomas Dohmke, former CEO of GitHub. His first product reflects a sharp insight: The thing GitHub gave us for human code, i.e. a complete, traceable history, doesn’t exist yet for AI-generated code.
Entire’s first open-source product, Checkpoints, integrates directly with Claude Code (and Gemini CLI). Every time you make a commit, Entire records a checkpoint which is a snapshot of what happened in that session, written to a shadow Git branch (entire/checkpoints/v1). The checkpoint includes:
- The full conversation transcript (
full.jsonl) - Session metadata: agent model, token usage, files touched, attribution percentages
- The prompt(s) that directly triggered the commit (
prompt.txt)
Critically, this data lands in your own repository. There’s no third-party vault, instead the shadow branch is just another branch, accessible with git fetch.
All the information is also available in the Entire UI
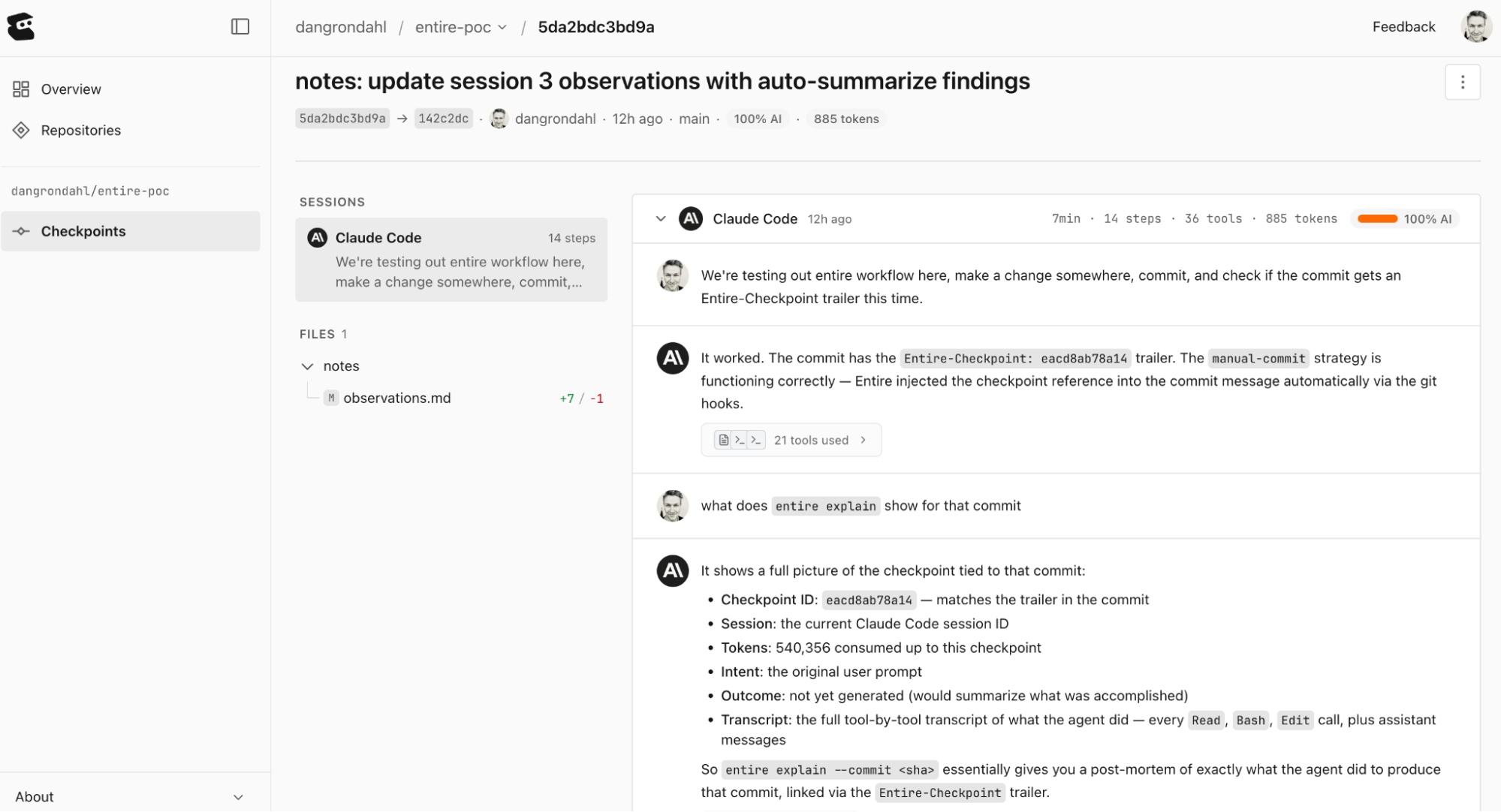
Kosli: Compliance as Code for Your Delivery Pipeline
A core primitive in Kosli is an attestation: Structured evidence about a software artifact, or activity attached to a Kosli trail. Custom attestation types can have JSON schemas and jq compliance rules that evaluate whether the evidence meets your policy. Trails that pass all required attestations are COMPLIANT and those that don’t are NON-COMPLIANT.
Kosli doesn’t need to care what your evidence is, only that you recorded it and that it matches the schema you agreed to.
What I Built
My idea was to treat Entire’s checkpoint data as attestation evidence in Kosli. Wire it up in GitHub Actions so that every push automatically reads the shadow branch and posts structured evidence for any AI-assisted commit.
Step 1: A Custom Attestation Type
Kosli allows custom attestation types with a JSON Schema and an optional jq rule. I created entire-attribution:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"required": \["checkpoint", "commit", "files_touched", "attribution"],
"properties": {
"checkpoint": { "type": "string" },
"session_id": { "type": "string" },
"agent": { "type": "string" },
"files_touched": { "type": "array", "items": { "type": "string" } },
"token_usage": { "type": "object" },
"attribution": {
"type": "object",
"required": \["agent_percentage"],
"properties": {
"agent_percentage": { "type": "number" },
"human_modified": { "type": "number" }
}
},
"intent": { "type": \["string", "null"] }
}
}
Theintentfield, the last message fromprompt.txt that triggered the commit, turned out to be philosophically interesting. More on that below.
Step 2: The CI Workflow
A GitHub Actions workflow runs on every push, iterates over the pushed commits, and for each one that has an Entire-Checkpoint: git trailer:
- Reads
metadata.jsonfrom the shadow branch - Extracts the triggering message from
prompt.txt - Builds a structured JSON attestation
- Posts it to Kosli as
entire-attribution
The shadow branch is already public on GitHub as Entire’s pre-push hook writes it before your main refs land. No extra infrastructure needed.
Step 3: Tool Audit
The attribution attestation tells you what was produced. The tool audit answers a sharper question: was the agent allowed to do what it did?
Claude Code has a settings.json where you can define deny rules which are tools or file patterns the agent must not access. I added:
"permissions": {
"deny": [
"Bash(rm -rf *)",
"Read(./very-secret-folder/\*\*)"
]
}
Then I, well Claude, wrote a Python script that:
- Reads
full.jsonlfrom the checkpoint - Extracts every tool call the agent made
- Checks each one against the deny rules in the committed
settings.json - Reports violations
This creates a second attestation type, entire-tool-audit, with a jq compliance rule:
.violations_count == 0
Any trail with a violation becomes NON-COMPLIANT in Kosli.
The Threat Model This Actually Catches
The tool audit is aimed at a specific attack: a developer removes a deny rule from settings.json before a session, and thereby giving the agent broader permissions, then reverts settings.json before committing, so the repository looks clean.
What they can’t clean up is the transcript. The full.jsonlrecords every tool call the agent made during the session. CI fetches it from the shadow branch, compares it to the policy the repo now claims was in force, and catches the discrepancy.
Two things I confirmed empirically:
settings.local.json cannot override deny rules
You can add to the allow list locally, but deny rules in settings.json are absolute. The only way to bypass them is to remove them from settings.json directly.
- Checkpoint persistence only happens for the first commit of a session
Subsequent commits in the same session haveEntire-Checkpoint: trailers in git, but the shadow branch data isn’t fully written until the session ends. This means the tool audit only works reliably when the demo scenario is a fresh session. Something worth putting a bit more investigation in.
The Harder Question: Can You Govern Intent?
While building theintent field, I ran into something worth pausing on.
It’s tempting to write a jq rule like: flag commits where the agent wrote >90% of the code, the human made no edits, and the prompt was short. This would try to identify “low-oversight” commits, that is, cases where a developer handed off a task entirely and rubber-stamped the result.
But consider the proxies:
agent_percentage > 90%:High agent contribution is normal and often desirable. It doesn’t indicate low oversight. A developer who carefully reviews a large AI-generated diff has exercised plenty of oversight.human_modified == 0:This counts file edits, not cognitive engagement. A developer who prompts for corrections rather than directly editing files registers as human_modified = 0 despite meaningful involvement.Short prompt:Experienced developers often write terse, precise prompts. “Refactor this to use the repository pattern” isn’t low-intent; it’s high-trust brevity.
Every proxy measures actions, not cognition. The gap between them is exactly where intent lives.
The conclusion: intent cannot be gated by automated rules without generating false positives that punish good actors. What you can do is record the evidence honestly, that is the prompt, the attribution percentages, the token usage, and let human judgment (in a review, an audit, an incident investigation) interpret it. Pure evidence is more durable than automated gates built on weak proxies.
I removed all evaluation rules from the attribution attestation type and left it as observable evidence only.
The Privacy Side of Recording Prompts
Recording prompts as evidence creates two legitimate concerns that any team adopting this pattern should think through explicitly.
The “spying” question. Prompts are often more candid than commit messages. A developer might write “this code is a mess, just rewrite the whole function” or describe internal context that wasn’t meant to be a permanent record. Knowing that every prompt is stored and potentially reviewed by auditors or managers changes the way people write them, and not always for the better. The chilling effect is real.
There’s no clean answer here. You can treat it the same way you treat code review: the work product is observable, the private thought process isn’t. But prompts sit in an uncomfortable middle as they’re more personal than code, but they’re also the clearest signal of intent you have.
Secrets in prompts. I haven’t tested what happens if a secret lands in a prompt, whether Entire redacts it, warns about it, or stores it as-is. That’s worth verifying directly with Entire’s documentation or the team.
My working assumption, though, is the same mental model that applies to Git history: don’t put secrets there. We already have a shared understanding that secrets don’t belong in commit messages, code comments, or tracked files. The same discipline should extend to prompts. The shadow branch is a Git branch. Treat it accordingly.
The broader point: recording prompts is a governance benefit and a privacy cost. Teams should make that trade-off consciously, not by default.
What the Evidence Vault Looks Like
After a few sessions, a Kosli trail for a commit looks like this:
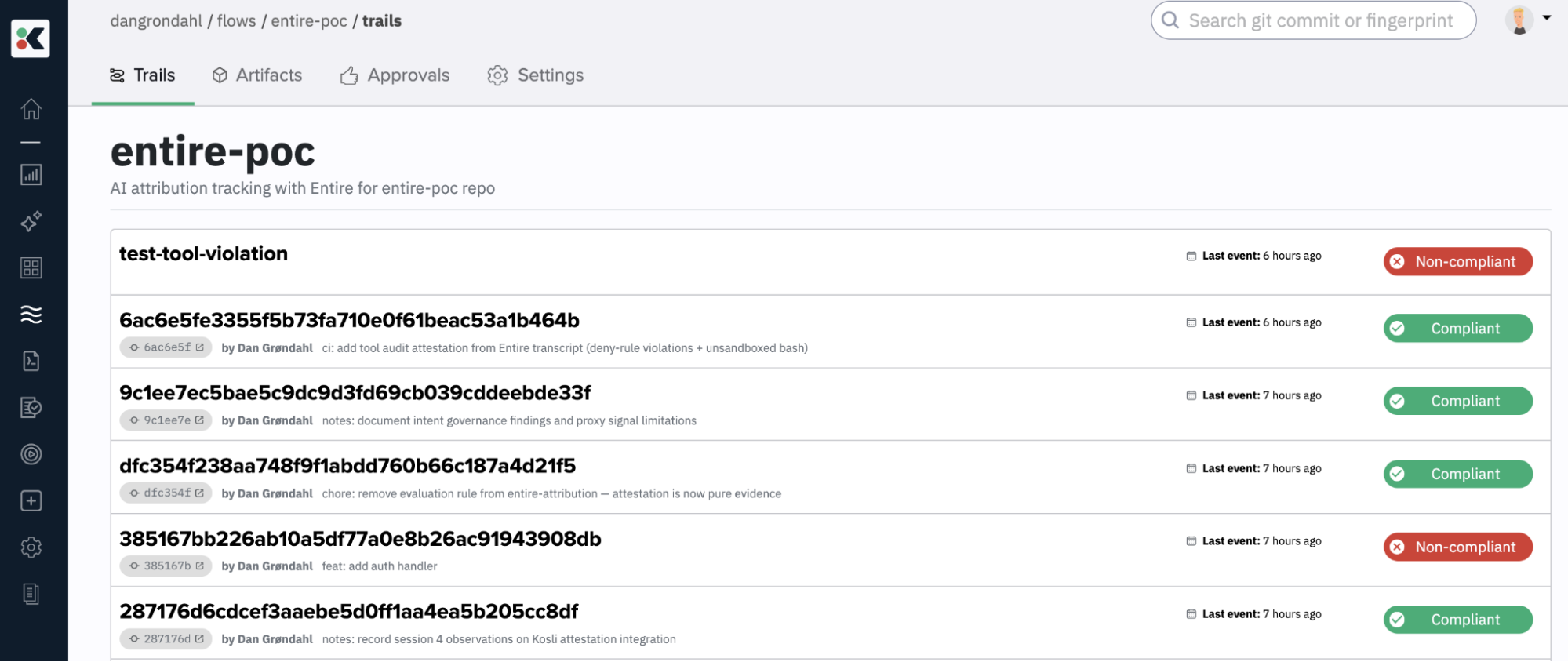
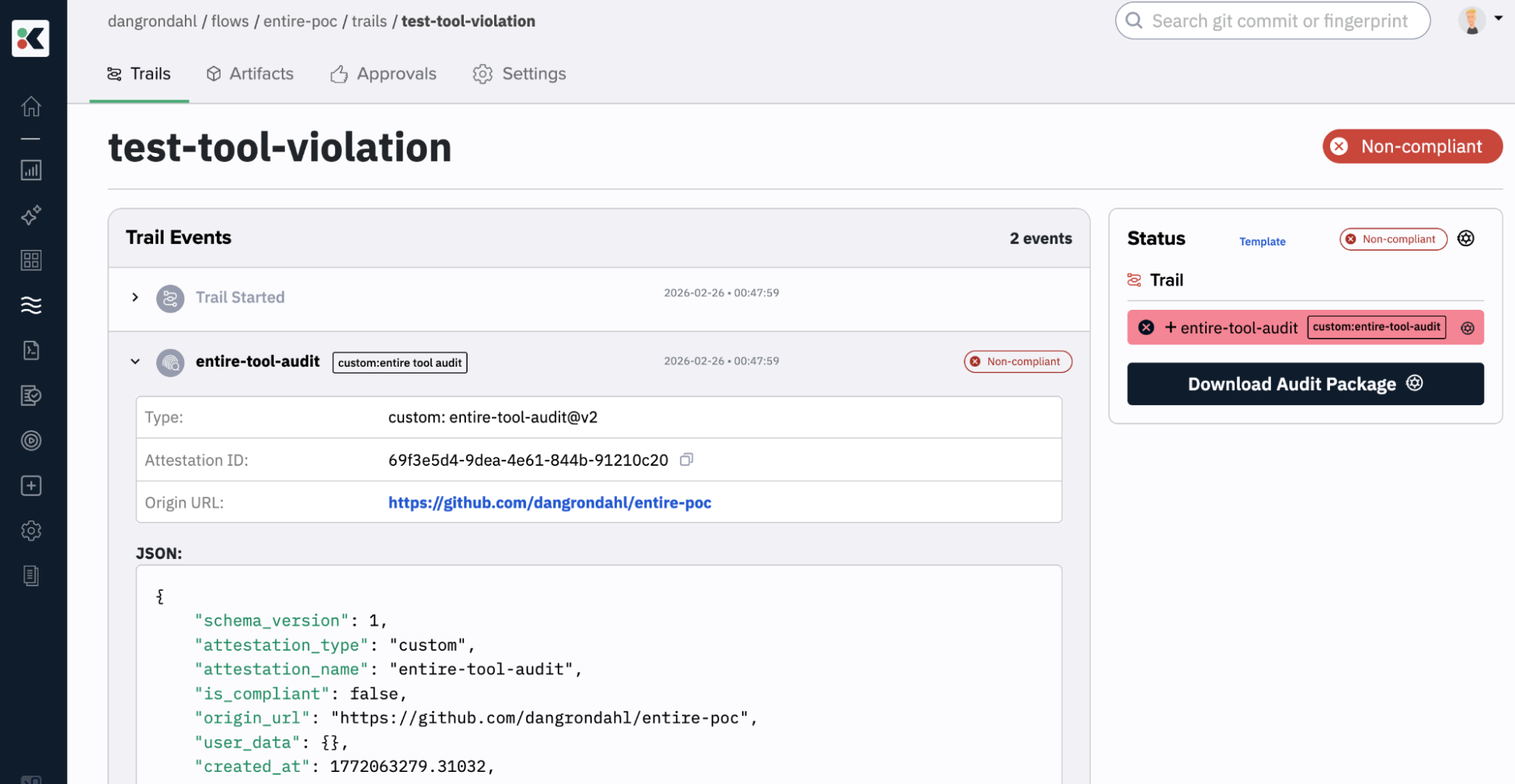
When a violation occurs, the tool-audit row flips to NON-COMPLIANT, and you can trace exactly which tool call triggered it, what file it touched, and which deny rule it matched.
Here’s a COMPLIANT trail with the two attestations:
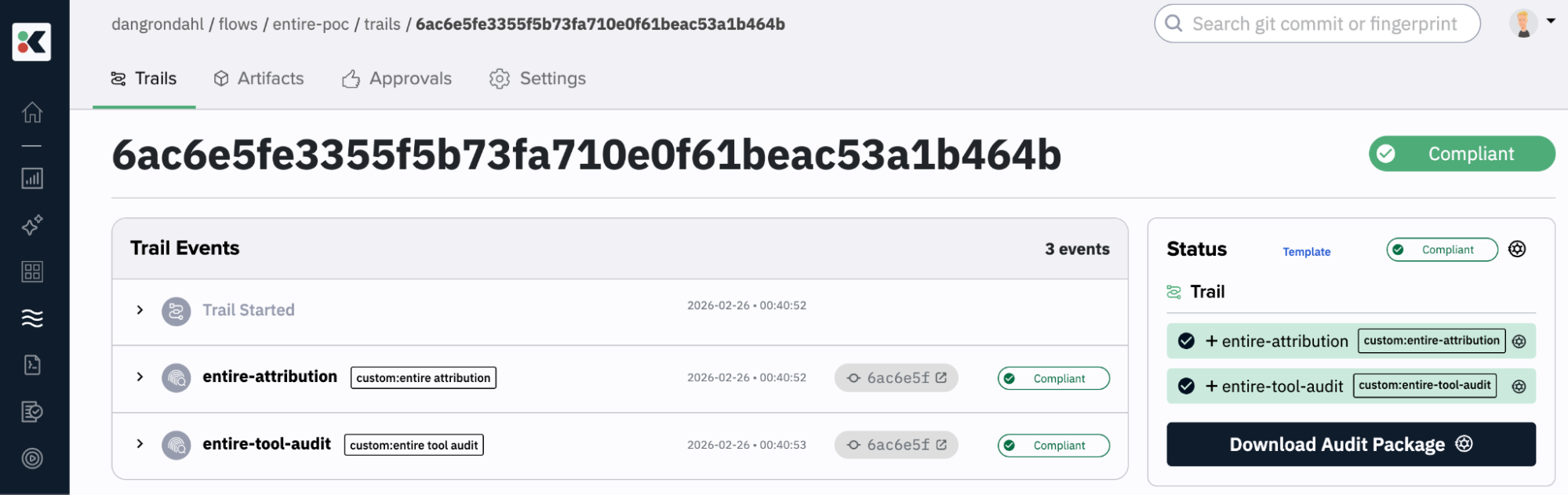
If we zoom in on the entire-attribution attestation, we can see the attached prompts I gave Claude.
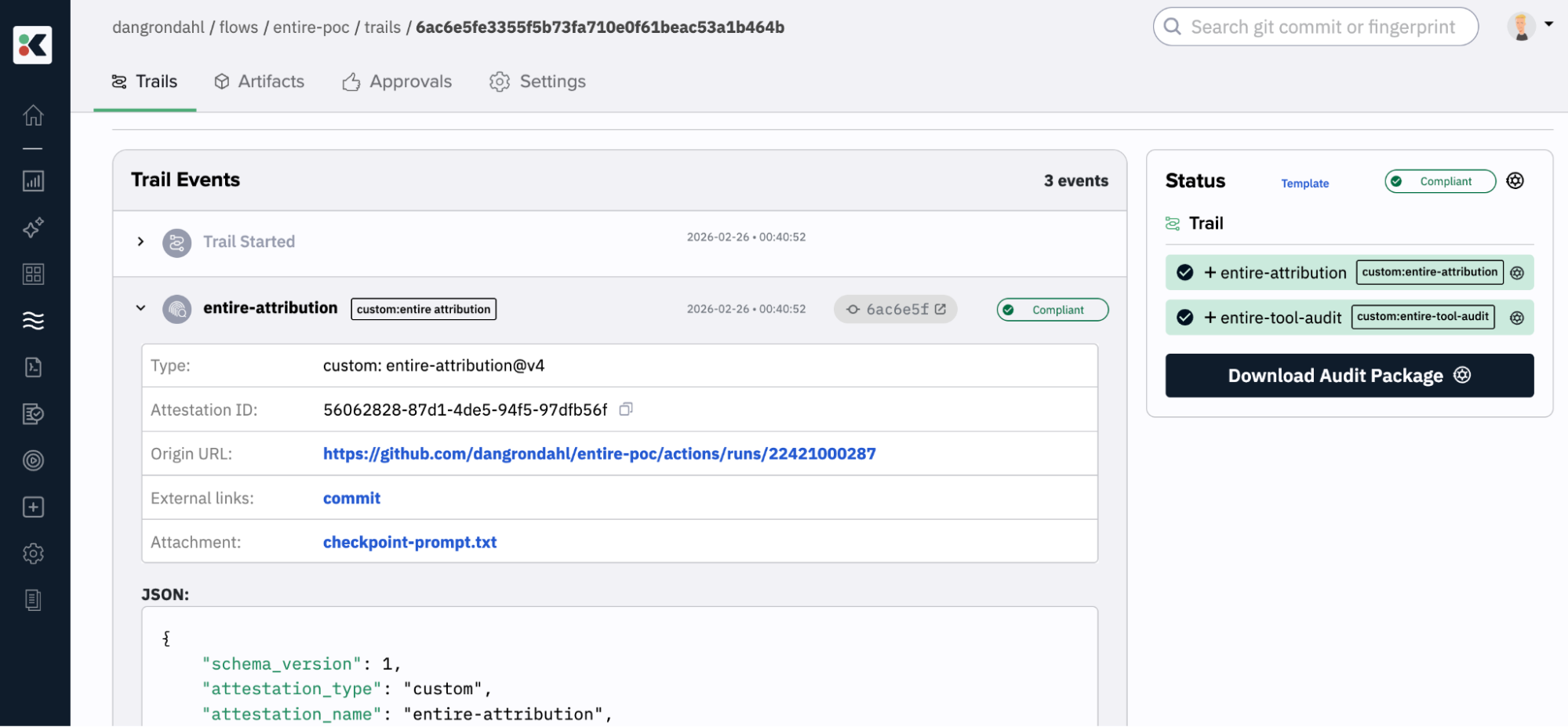
Here’s a snippet of it:
\---
Working, but the data is not very usable. Can we try to run:
\`\``
entire explain --commit $(git rev-parse HEAD) --raw-transcript --checkpoint <checkpoint>
\`\``
Insert checkpoint
\---
philosophical question: How can we evaluate and govern intent with our prompts? What is a good intent vs. a bad intent and what's the spectrum?
\---
Interesting, can we do this as a combination with jq rules as you suggested? It would mean to also provide a schema for the custom attestation
\---
We need to update the flow template
\---
Let's test with a prompt that would be seen as non-compliant?
\---
Let me try a bad prompt... coming up
\---
Add stuff to the docs
\---
Similarly here’s a NON-COMPLIANT trail where I removed a denied tool in the settings.json before the start of a session. This one I ran locally for testing.
What I Learned
The plumbing is simpler than you’d expect
Entire’s shadow branch is a plain Git branch. Kosli’s custom attestation type is a JSON schema and a jq expression. Connecting them was just a few dozen lines of Python and YAML.
The hard part is policy design, not tooling
Deciding what you want to attest, what counts as a violation, and what stays as evidence rather than a gate is a governance design problem, not a technical one. The tools give you surface area; you still have to think.
Behavioral proxies are fragile
If you want to build compliance rules, build them around things you can observe cleanly: specific tools, specific file paths, specific permission levels. Avoid rules that try to infer intent from indirect signals.
The timing constraint is real
Entire’s checkpoint persistence only covers the first commit of a session. If your workflow involves committing multiple times in a long session, the later commits won’t have shadow branch data for the tool audit. Design your workflow accordingly or push the agent toward single-commit sessions where intent is clear.
Provenance without judgment is still valuable
… But be explicit about what you’re recording.
Knowing that a commit came from checkpoint a3f8c2…, that the agent touched these nine files, that the token usage was this high, and that the triggering intent was this prompt, that is information that didn’t exist before. It changes the character of a code review, an incident postmortem, and an audit conversation. But prompts are more personal than code, and the shadow branch is permanent Git history. Be deliberate about who can see it, tell your team it exists, and treat it with the same discipline you apply to anything else that goes into a repository: no secrets, no content you wouldn’t want in a compliance review.
Where This Goes Next
The experiment left a few threads open:
- Richer policy: deny rules on specific tools or file patterns are just the start. You could attest which MCP servers were active, which models were invoked, whether any web fetches hit external domains.
- Review attestation: a human approval step: “I reviewed this checkpoint and found it acceptable” should be a separate attestation type on the same trail.
- Cross-commit analysis: Kosli’s API makes it possible to query across trails. What percentage of your commits over the past quarter had agent involvement above 80%? Which sessions triggered tool audit violations?
None of this requires waiting for AI governance frameworks to mature. The infrastructure exists today.
All code from this experiment is on GitHub at dangrondahl/entire-poc. The CI workflow, tool audit script, and Kosli attestation schemas are in .github/workflows/ and .kosli/ respectively.