

To ensure binary provenance in your software development process you must, among other things, have confidence that the artifact doesn’t change. If you use a code review and test result as an assurance that it’s a valid and reliable artifact, the binary or Docker image you’ve reviewed and tested should be the same one you deploy later.
Applying the SHA-256 algorithm
One way to solve this is to give your artifact a unique, immutable signature - something that will not change unless the artifact itself changes. The SHA-256 algorithm can serve as such a signature and that’s what we use in Kosli. It’s calculated when your artifact is built and you can recalculate it at any point in the future to check that it’s still the same object. If the SHA-256 signature doesn’t match then it is not the same artifact and if you can’t determine where it came from it may pose a security risk.
When you report an artifact to Kosli all sorts of information becomes available. You can see where and when it was built and which repository and commit were used to build it. Before it is deployed to a production environment there is a whole process the artifact has to go through, including a number of risk controls. For example, you may need to confirm there was a properly reviewed pull request created before it can go to the main branch. The artifact probably has to be tested and there can be a lot of different types of tests, both automated and manual. Sometimes the artifact has to be approved by a specific person.
Whenever any of these events happen they can be reported to Kosli where the SHA-256 is used to identify which specific artifact the event (logged as “evidence”) refers to.
Docker images as artifacts
You can always calculate the SHA-256 of any file or folder on your own. Kosli does that for you when you report an artifact or evidence to it, but sometimes the SHA-256 is available almost out of the box. When you pull a Docker image from the registry you can read the digest using docker image ls --digests. As a result you’ll get a list of all the images currently on your machine and some details about them, including the digest which is our SHA-256.
You can also use the docker inspect [image:tag] command that will show you detailed information about specific images, including the SHA-256.
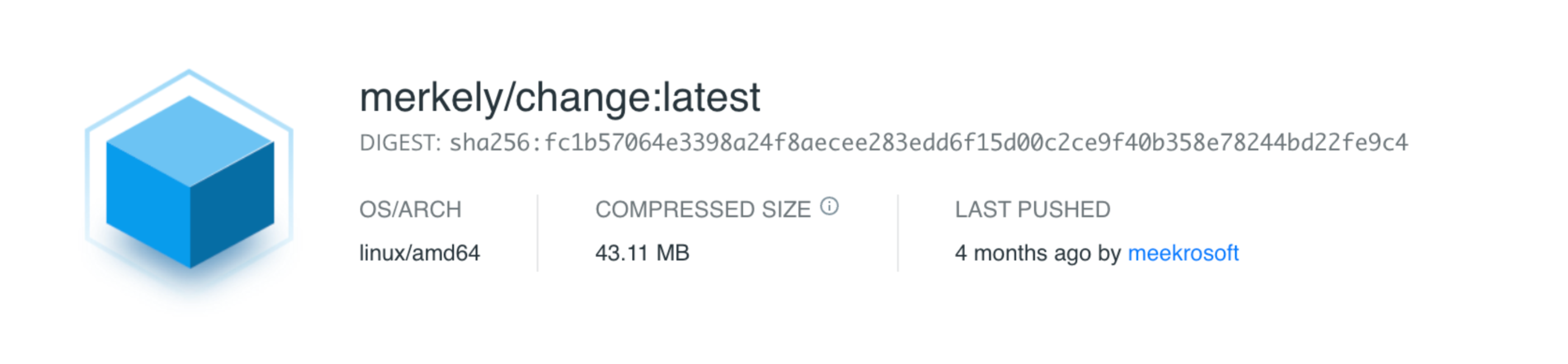
You can also check it directly in your Docker registry. For example, at https://hub.docker.com/, when you’re looking at a specific version of the image you can find the digest at the top of the page.
If you’re trying to automate the process of getting a Docker image’s digest, and can’t be sure Docker will be available on the machine where you run your tool, you may decide to use the Docker registry API to request the image manifest. This will contain information about the image including layers, size, and digest. Once you make the request and get a response with a manifest you can parse it to retrieve the digest. Depending on the tool or language you’re using there are a lot of different ways of doing this. Here is an example of how we do it at Merkely: cli/internal/digest/digest.go
Can an immutable SHA-256 change?
If you check digest.go you may notice we declare two different types of manifest. And that is where things start to get interesting.
At first we were only using the regular "application/vnd.docker.distribution.manifest.v2+json" manifest type. It was the one appearing in most of the examples of how to use the Docker registry API. Getting a manifest from the Docker registry using an API is a two step process. First you need to generate a short-lived bearer token using the username and access token you configured in your registry provider. For the purpose of the example below we’re using https://hub.docker.com/ and the variables DH_USER and DH_TOKEN contain the information required for authentication.
You can generate a temporary bearer token using e.g., curl:
DH_TMP_TOKEN=$(curl \\
\--silent \\
\-u "$DH_USER:$DH_TOKEN" \\
"https://auth.docker.io/token?scope=repository:library/mongo:pull&service=registry.docker.io" \\
| jq -r '.access_token')Pay attention to the url in the command above. Each token is generated only for a specific repository in a registry. You need a new token if you want to request the manifest for an image from a different repository.
Once you have your temporary token you can ask for the manifest of a specific Docker image. Again, we rely on curl to do this:
curl \\
\--silent \\
\-X GET -vvv -k \\
\--header "Accept: application/vnd.docker.distribution.manifest.v2+json" \\
\--header "Authorization: Bearer $DH_TMP_TOKEN" \\
"https://registry-1.docker.io/v2/library/mongo/manifests/3.6" 2>&1 | grep -i -e docker-content-digestOur CLI tool does exactly the same thing, but it uses different methods to send requests and process the responses.
While working on a pipeline for one of our customers we realized that digests returned by our CLI tool, docker image ls --digests command and https://hub.docker.com/ - for the same image - were in fact not the same. This was initially very confusing and it was difficult to see any logic in the inconsistency.
Things became clear after some research. It turns out that we were asking for a regular manifest (application/vnd.docker.distribution.manifest.v2+json) while in some cases a “fat manifest” (application/vnd.docker.distribution.manifest.list.v2+json) was also available.
A fat manifest is a manifest list and it points to specific image manifests for one or more platforms, so there actually was some logic to the inconsistency. A quick look at the numbers made it clear that e.g., Docker CLI and K8s in some cases were providing the data from the fat manifest, while our registry API request (as you can see in the command above) was returning a regular manifest.
How to get the right Docker digest
Some of the images were built for different platforms and, depending on the architecture of the machine we used to pull the image, we were getting different digests for (theoretically) the same image. While we understood the problem we simply couldn’t accept different digests for the same image.
We had to find a solution where we’d always get the same digest for a given image, no matter where or how we’d requested it. And the fat manifest comes in handy in this case. The tricky part is figuring out if the fat manifest actually exists for a given image. You can always ask for the “fat manifest” but you’ll only get it back if it actually exists.
Here is a recipe for getting consistent results no matter the platform (for the purpose of our CLI we’ve decided to do exactly the same thing):
- Ask for the fat manifest first (
application/vnd.docker.distribution.manifest.list.v2+json) by modifying header in your request - When you get the response validate if you got the fat manifest back or a different one, by checking the “
Content-Type” - If you got the fat manifest back, the
docker-content-digestheader in the response will contain the correct digest - If you got something else (for example we were getting
Content-Type: application/vnd.docker.distribution.manifest.v1+prettyjwswhen there was no fat manifest available for a given image), send another request. This time ask for the regular manifest (application/vnd.docker.distribution.manifest.v2+json) and check for thedocker-content-digestresponse header. This is the correct digest.
And that is how we figured it out! 🥳
Conclusion
So, the answer to the question posed in the title is: no, Docker images and their digests aren’t mutable, but you have to make sure you are looking at the correct digest.
We get reliable digests back from the registry when we use our CLI. Try it out if you’re looking for a tool that can easily read image digests from the registry: https://docs.kosli.com/client_reference/kosli/
This was a short and bumpy ride, but it was also a great learning experience and it should offer a solution to those of you experiencing the same issue.




