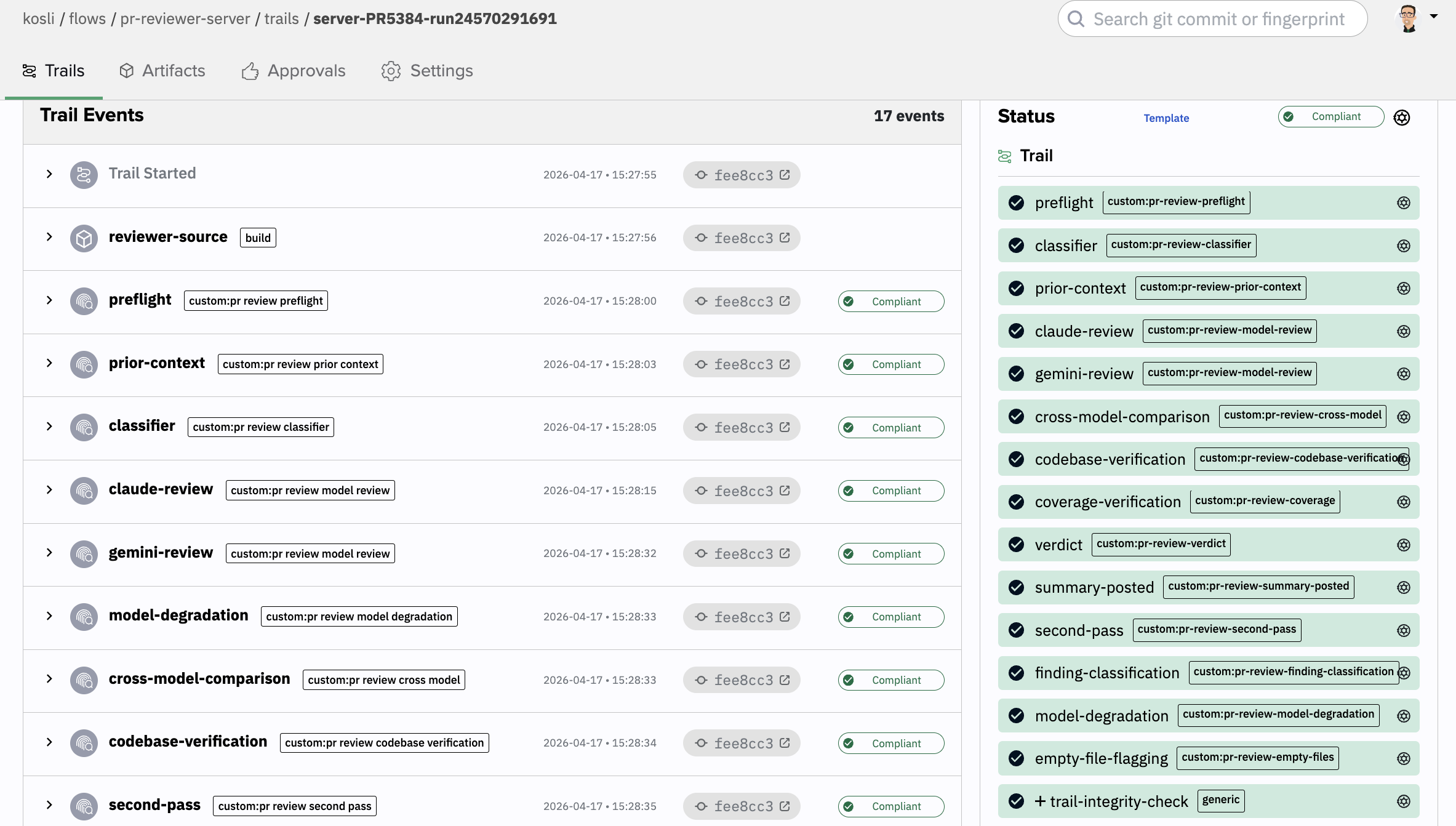

We’ve built a multi-LLM PR reviewer that runs on every pull request in a couple of our own repos. Two independent models look at each change in parallel, each wearing a set of “persona hats” tuned to a specific area of the codebase. They compare notes, duplicates get stripped out, and the PR author ends up with a single review comment rather than a wall of noise. It also reviews its own pull requests, and there’s a feedback loop behind it that retrains individual personas when they start to drift.
Why personas
The honest answer is that a single “please review this PR” prompt produces shallow, generic findings. We tried it. It wasn’t useful enough to put in front of an engineer.
Splitting the work into narrow domain experts changed the quality quite a lot. A security persona looks for the things a security engineer would look for. A test quality persona digs into whether the rainy-day cases are covered. A database persona worries about query patterns and read-store consistency. No single prompt holds all of those lenses at once. Several smaller, focused prompts can.
Running the same persona set across two different models gives us a useful cross-check on top. The models genuinely catch different things. On a recent multi-file PR they only agreed on 28% of findings, with each model raising several the other missed entirely. On another PR one model wanted to approve and the other wanted to request changes, on the same single file. That kind of disagreement is exactly the signal we want, because it’s the bit a single-model reviewer would have hidden from us.
The other thing we really like about the persona shape is that it’s tuneable. When a persona starts getting things wrong, we retrain that persona. The rest of the system is left alone. It’s a much more surgical way to improve the reviewer over time than tweaking one giant prompt and hoping for the best.
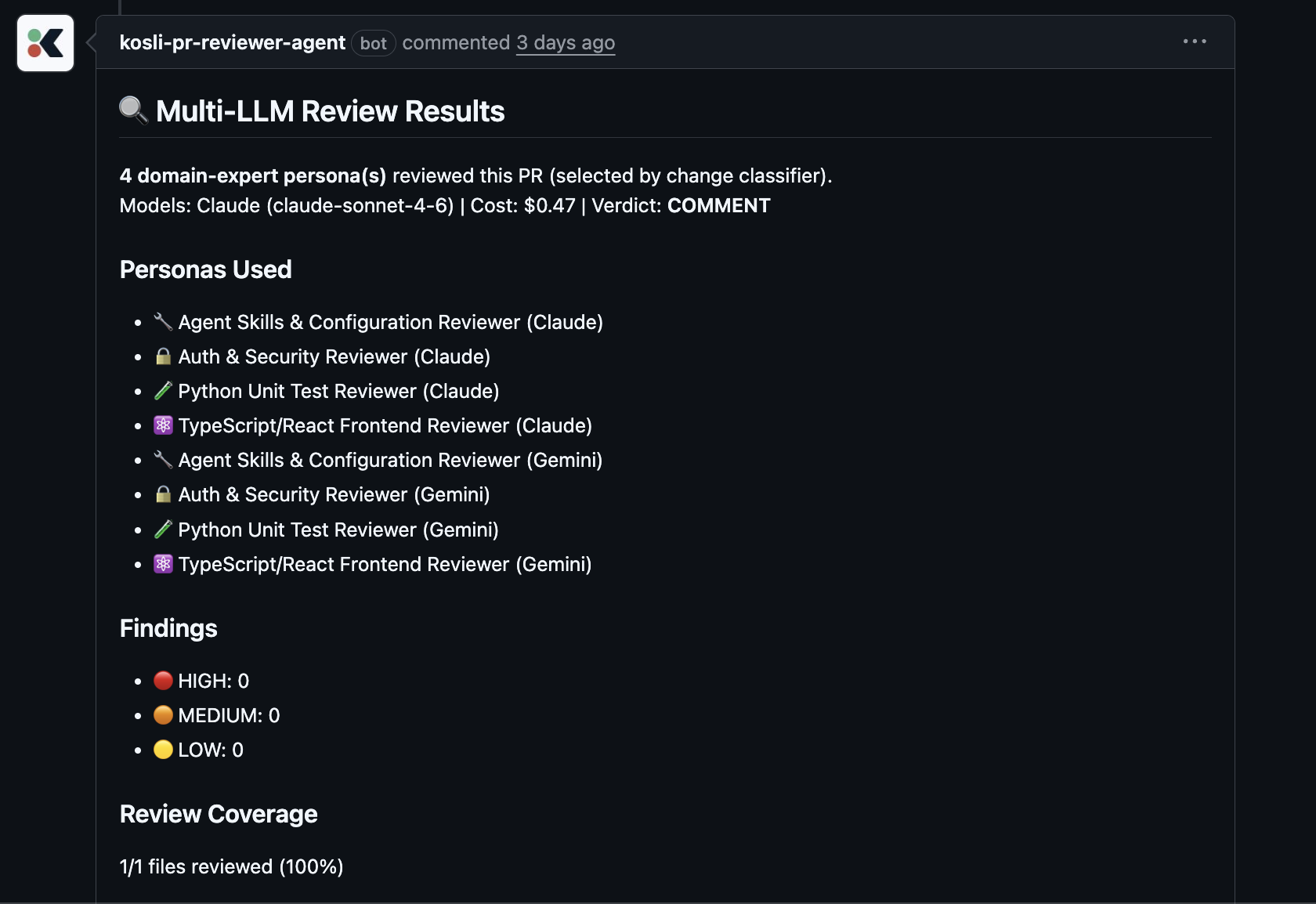
How Kosli helps us keep an eye on the controls
The reviewer is a pipeline with a lot of moving parts. Routing files to the right personas, checking that every changed file actually got reviewed, deduping findings, handling it gracefully when one of the models falls over. Without attestations, we’d just be trusting that the logs tell the truth. That’s not good enough for something about to comment on our engineers’ code.
Every review run is now a Kosli trail with attestations at each step, and a few things have been genuinely valuable in practice.
We can prove which version of the reviewer ran. The reviewer’s source is fingerprinted on every run, so if a review later looks strange we can trace back to exactly which version produced it.
Every step leaves evidence, including the steps that didn’t run. If the second pass wasn’t triggered because coverage was already 100%, that’s recorded with the reason. If one model degraded and the other carried the review, that’s recorded too. We never have to guess whether a step was skipped legitimately or quietly failed.
A policy at the end of the run checks the seams between steps. The interesting bugs in a pipeline like this sit in the joins, not inside any one step. The routing picked five personas but only four ran. Coverage said a file was reviewed but no persona was attributed to it. Both models failed but a verdict came out anyway. The trail-level policy catches all of that, and the result of that check is itself attested.
The shift for us is that we’re no longer in a position of “trust the bot”. We’re in a position of verify the bot, on every run, with evidence we can come back to weeks later. An AI reviewer is only as trustworthy as the controls around it, and getting those controls right is most of the work. The model is almost the easy bit.