A hot take 🔥🔥 from a kind place.
Before I start throwing sparks around I want to make clear that I think there’s lots of benefits to capturing everything as code in git. Static definitions, recipes and specs for how we make our software are useful in all kinds of ways. 🌈
However, those definitions don’t help us to understand our dynamic environment and that’s my essential problem with GitOps. Lots of claims are made for GitOps - it offers better security, historical records, and a solution to drift and reconciliation. I find myself wondering whether any of this is really true and in this article I’ll explain why.
GitOps makes me think of the old Hans Christian Andersen tale, about what’s real and what’s imagined. The emperor declares he’s wearing clothes, but what if he’s actually not wearing anything at all?
What is GitOps?
Before we dig in, let’s set a baseline for what we describe as GitOps based on weavework’s four principles
- The entire system is described declaratively.
- The canonical desired system state is versioned in Git.
- Approved changes that can be automatically applied to the system.
- Software agents to ensure correctness and alert on divergence.
Just like the agile manifesto, these four principles are pretty easy to accept. But, as with agile, turning theory into practice is the interesting part.
"I saw the best minds of my generation destroyed by madness...while trying to set up continuous integration."
— Austin Bingham (@austin_bingham) August 18, 2022
What does GitOps look like in practice?
Gitops strongly centers on the idea of software agents continuously running to converge system state with desired state.

So, how do we reconcile these states using a typical GitOps approach?
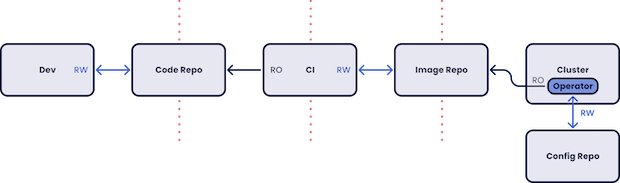
We install an operator (or agent) into our cluster which “pulls” (more on that later) the desired state from a git config repo, makes decisions, and adjusts workloads accordingly.
This is offered as an alternative to a standard DevOps pipeline which “pushes” change to the cluster:
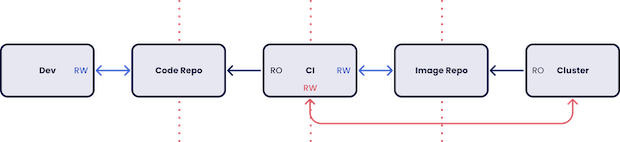
Ok, so we’ve outlined the theory and described the basic practice. Now for the upsides for GitOps. How do they materialize when we start to implement?
Extra security with GitOps? 🧐
First up - added security. What’s the benefit of taking the “pull-based” approach as opposed to simply pushing a change to our cluster? The main advantage is that with GitOps your CI server doesn’t have production access, so we can say that this improves our security.
| Traditional | DevOps | GitOps | |
|---|---|---|---|
| Infrastructure | Imperative | Declarative | Declarative |
| Desired State | Untraceable | Versioned | Versioned |
| Change Approvals | Tickets | Pull Requests | Pull Requests |
| Deployments | Manual | CI Event | + GitOps Operator |
| Security | Manual | Secrets in CI | + Secretes in infra |
However, is there really any additional security in this setup? If the CI system can update configurations, how does GitOps prevent rogue workloads from being deployed by a malicious actor with access to CI? 🤔
Versioning and environment history
Another major selling point for GitOps is the versioned history for the environment. That is kinda true, but you also get this with plain old DevOps assuming your pipeline and deployment information is in the source repo. This history is useful, but it isn’t a true record for how environments have actually changed (more on this later).
Rollback
Is rollback simpler with GitOps? I’m of the opinion that you’re better off with regular old DevOps by just reverting the commit. The benefit here is that it makes rollback a standard developer workflow and versioned with the source repository. Something doesn’t work? Simply git revert
Disaster recovery
What happens when your whole cluster goes down? What happens when you want to bring up a new cluster? Those are fair questions. But most teams aren’t rolling out blue/green clusters. Most companies have a static cluster/clusters. Most disaster recovery wouldn’t be hampered with the need to run deployment pipelines, and I think this should be scripted without the need for GitOps.
So, yeah, I’m skeptical about the benefits. But I have more reservations when we start to look at the trade-offs we have to make when we implement GitOps. Let’s take a look at those.
The challenges with GitOps
The first big challenge with GitOps is the effect it has on our pipelines. Splitting the deployment away from the earlier stages of the pipelines causes them to become distributed. From a value stream perspective this makes it hard to understand the overall path from commit to production. It disconnects earlier stages of qualification from later ones.
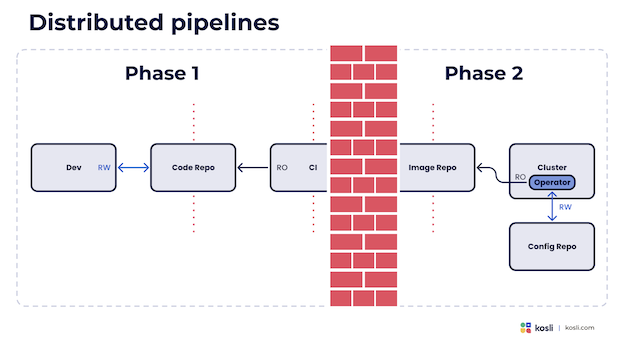
This matters because it removes the developer feedback from the value stream. In this setup, if a deployment fails, where does the feedback come from? How do developers get information on the deployment process? How can they enhance the deployment process with their own notifications? How can they improve the deployment process?
The second side effect is that separating these stages into two toolsets increases the gap between development and operations.
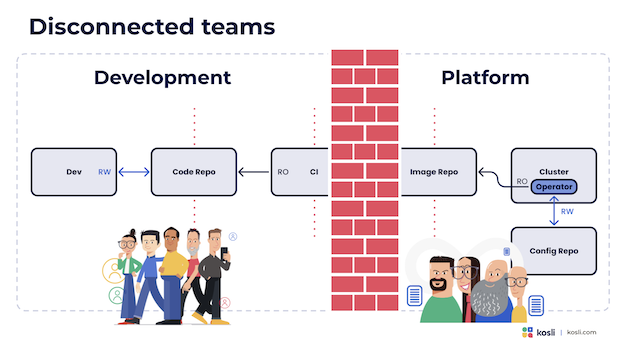
Typically the GitOps tooling is run and managed by a central platform team. Often the CI system is in the domain of the team. As Marshal McLuhan said, “We shape our tools and thereafter our tools shape us”.
The gap is widened even further by using a separate config repo to store the desired states:
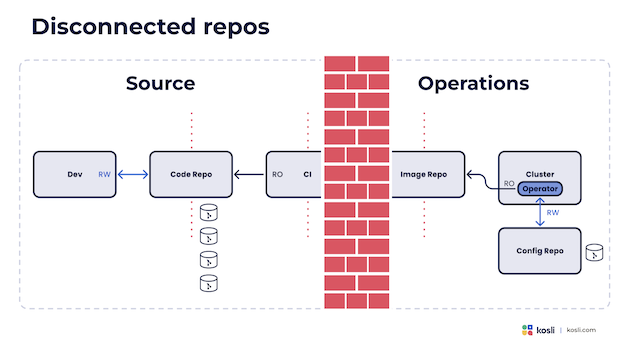
It is common to have git repositories centered around individual microservices with a separate common repo for describing the desired state of environments. One is code and developer centric, one is operations centric. Also, it is not unusual to have to write glue pipeline scripts to update the config repo.
Revisiting push vs. pull
The major innovation in GitOps seems to be to move the operations to a pull-based model. This seems like a big change, but on closer inspection I don’t think it’s actually true. [Thanks to my good friend Henrik Hoegh for spelling this out to me]
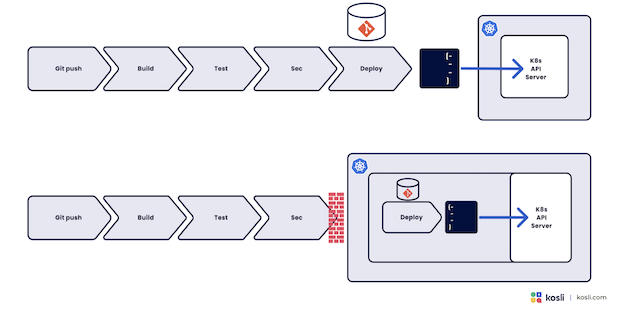
Typically, a GitOps operator reads a config from a git repo, applies zero-to-many transformations on it, and then pushes it into the kubernetes API server. Which is exactly what your deployment tool does in the push based model! With GitOps we distribute our pipeline over two asynchronous tools, using a git repository as a semaphore, but with both approaches we push changes into our cluster.
It’s great for Drift and Reconciliation though, right?
Another big headline advantage of GitOps is the reconciliation loop - the automated repairing of any drift or manual change. Any undocumented changes are erased and the environment is reconciled with the git definition.
At face value, this seems like a massive bonus. However, I take a different view on this too. Before we jump to reconciling undocumented changes we need to ask why they have happened in the first place. Maybe we don’t want them reconciled? There could be a very good reason to do a manual change, and we might not want the environment to be automatically repaired.
Another reason might be sabotage, in which case we definitely want humans in the loop to investigate and manage the situation. In either case, configuration drift should cause a proper incident management process to take place, not just a slack message from a reconciliation loop that disappears into the ether.
And on the technical side, I feel that Kubernetes already has a reconciliation loop. You describe your deployments and configuration declaratively, and it is Kubernetes’ job to make that true. Layering reconciliation loops feels like adding unnecessary complexity.
The map git repo is not the territory
We like to think the git config repository is equivalent to how things change, but in reality there is a gap between these static definitions and what is actually happening in the dynamic DevOps automation. All this talk about GitOps providing a “Single Source of Truth” is simply not true. If I want to find out what was actually running on Thursday night there is no simple way to get there.
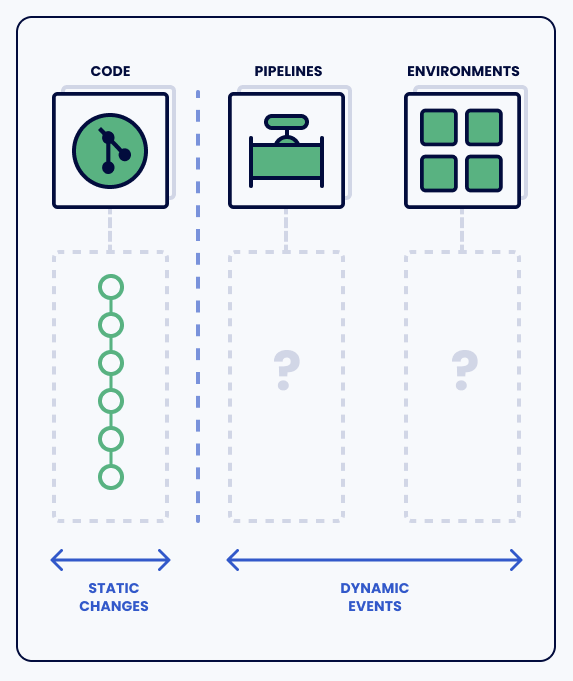
The GitOps configuration provides no insight into manual changes, scaling events, failed reconciliation and many other edge cases. These types of events cause incidents but GitOps provides no situational awareness when they happen.
When an incident occurs what we really need is to understand how things have actually changed. A big problem with modern GitOps is developers and ops teams having little or no true record of the actual changes that occur. We need to be clear that desired states are not actual states.
A static view of change is beneficial but limited
I began by saying that I’m all for putting the recipes, definitions, and specs for our desired DevOps in version control. It offers us all kinds of benefits. Let’s remind ourselves of what they are:
- Better transparency: enables sharing, reviewing and auditing in a familiar technology
- Code tools and workflows: enables branching/pull-request based approaches to integrate change
- Better Quality: allows you to add linters, checkers and static analysis in the automation processes, and enforces consistency of changes
- Immutability: helps minimize configuration drift
- Centralization: can help reduce “configuration sprawl”: the configuration of processes spread over multiple unconnected systems
So far so good - but every static definition has a dynamic execution. There are real events taking place, asynchronously and automatically, with results we need to record and understand.
| Static Definition | Dynamic Execution |
|---|---|
| Build script | Compilation/Packaging |
| Test suite | Test runs |
| Deployment file | Deployments |
| Docker file | Docker image builds |
| Infrastructure model | Infrastructure changes |
The dynamic world is, quite literally, where the action is. Working back from a GitOps definition to events, changes, ordering, and dependencies is not easy for developers.
If you’re still wondering why this matters, the google SRE book tells us that “70% of outages are due to changes in a live system.” So, when things go wrong, the dynamic world should be the first place we look for answers.
Conclusions - Who’s GitOps?
Much like the agile manifesto, the loose definition of GitOps means that it can and will be applied in all kinds of different ways. A broad church approach is the perfect nerd-snipe. Is terraform GitOps? Maybe? I dunno!
And like agile everyone experiences FOMO. What if this is the next big thing? Do we jump on the bandwagon for fear of being left behind? With agile we need to ask “who’s agile?” Maybe we need to ask “who’s GitOps?” As ever, what we really need to ask ourselves is - who are we serving with these tools and what problems are we trying to solve?
At the end of The Emperor’s New Clothes the people around the emperor continue to praise his new outfit, even as they come to realize he’s completely naked. It’s an embarrassing situation that any of us can get into when we go all in on something and want it to be true. Like the kid in the crowd who shouts “But the Emperor has nothing at all on!” sometimes it’s good to uncomplicate everything by just saying what you see.