Getting system test coverage from a Python web server is not straightforward. If you search the internet all the hits describe killing the server (eg gunicorn) to get the coverage exit handlers to run. When you run your server from a docker container this means the next test run is forced to bring up a new container. This slowed our test cycle which we didn’t like, so we found a faster way. We restart the server instead of killing it.
This blog post contains links to a public github Kosli demo repo tdd which contains:
- gunicorn running with multiple workers
- each running a simple Flask web server (with an API)
- the web server scores the XY Business Game by Jerry Weinberg
- system tests, running in parallel, with coverage obtained by restarting gunicorn
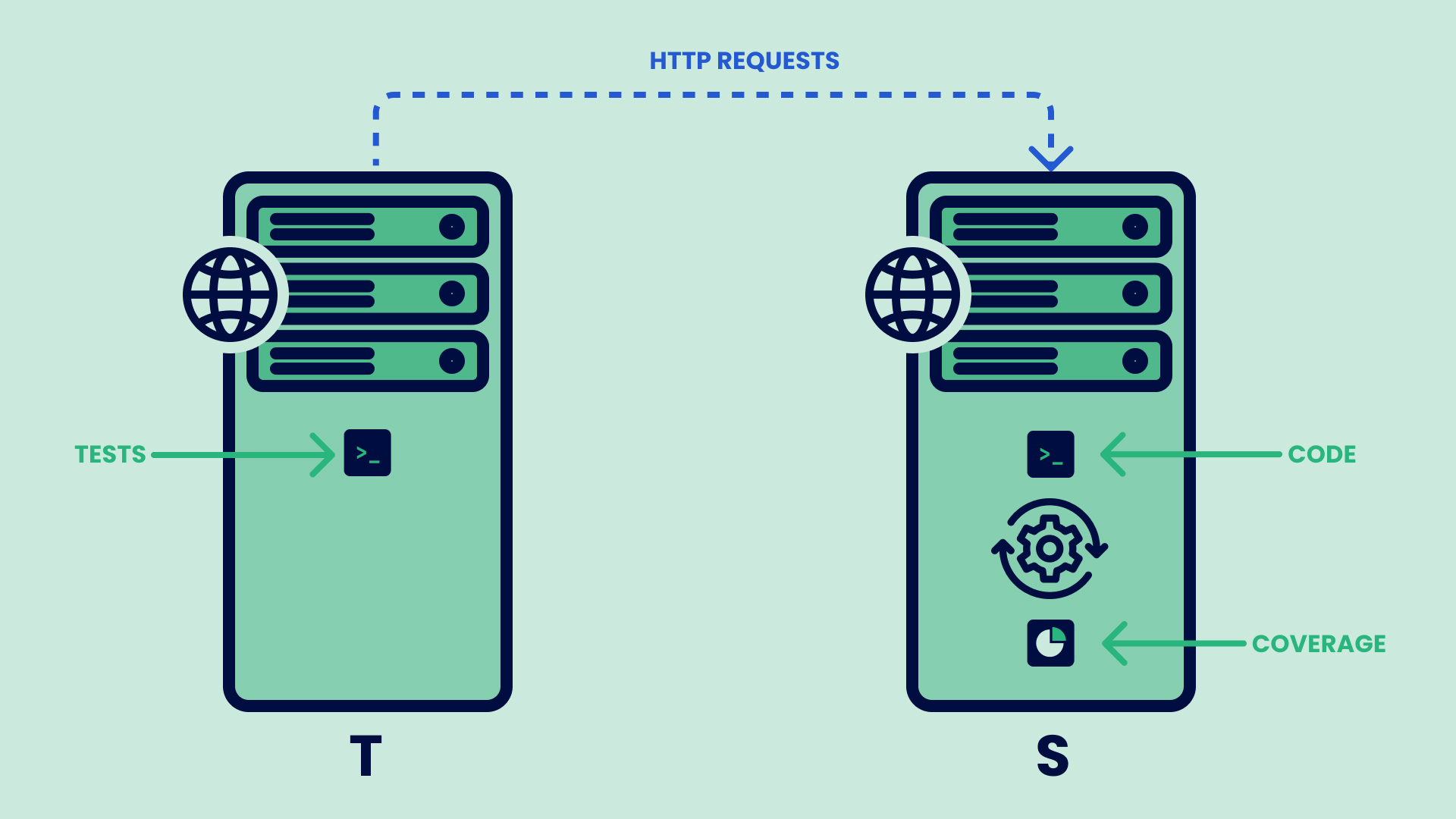
The Architecture
- The server is running inside a docker container S.
- The pytest-cov package is installed from
requirements.txt. - The code in S runs with coverage when in test mode.
- The system tests are running inside a different docker container T.
- The tests in T send HTTP requests to S.
- When all the tests in T have finished we have to extract the coverage from S.
Getting system-test coverage the slower way
- Create a file called sitecustomize.py as follows:
import coverage
coverage.process_startup()
- Ensure that, when testing, an environment variable called COVERAGE_PROCESS_START is set to the path of your
.coveragercfile inside S. Eg:
[run]
data_file=${XY_CONTAINER_COV_DIR}/.coverage
- Now bring up a server S, wait till S is ready, then run the tests from T. When the tests have finished, kill the server S. The coverage exit handler will run and write out the
.coveragefiles. - Ensure the directory specified in
data_file=is volume-mounted in yourdocker-compose.yamlfile so the.coveragefiles are not lost.
Getting system-test coverage the faster way
You do not need a sitecustomize.py file.
As before, when testing, an environment variable called COVERAGE_PROCESS_START is set to the path of the .coveragerc file inside S.
If the COVERAGE_PROCESS_START environment variable is set, our gunicorn.sh file starts gunicorn with the –config flag set to a file called gunicorn_coverage.py:
#!/usr/bin/env bash
set -Eeu
readonly MY_DIR="$(cd "$(dirname "${BASH_SOURCE\[0]}")"; pwd)"
if [ -z "${COVERAGE_PROCESS_START:-}" ]; then
COVERAGE_CONFIG=
else
COVERAGE_CONFIG="--config ${MY_DIR}/gunicorn_coverage.py"
fi
gunicorn \
...
${COVERAGE_CONFIG} \
--workers=2 \
...
The gunicorn_coverage.py file hooks into gunicorn’s post_fork handler to start coverage when a worker process starts, and into gunicorn’s worker_exit handler to stop and save coverage when a worker process exits.
import coverage
import os
import subprocess
cov = coverage.Coverage(config_file=os.environ["COVERAGE_PROCESS_START"])
def post_fork(server, worker):
recreate_coverage_dir()
cov.start()
def worker_exit(server, worker):
cov.stop()
cov.save()
def recreate_coverage_dir():
cov_dir = os.environ["XY_CONTAINER_COV_DIR"]
rmdir_cmd = ["rm", "-rf", cov_dir]
mkdir_cmd = ["mkdir", "-p", cov_dir]
subprocess.run(rmdir_cmd, check=False)
subprocess.run(mkdir_cmd, check=True)
Now, instead of killing the server to get the coverage, we can restart the server by sending a SIGHUP signal to the gunicorn master process. This brings up new worker processes and calls their post_fork() handlers, and brings down the old worker processes and calls their worker_exit() handlers. The recreate_coverage_dir() function relies on the former happening before the latter. The server is running inside an Alpine container so we use the -o flag to find the oldest gunicorn process which will be the master process:
restart_server()
{
docker exec --interactive "${CONTAINER_NAME}" \
sh -c “pkill -SIGHUP -o gunicorn”
}
The SIGHUP signal is asynrchronous so after sending it we must wait until the cov.stop() and cov.save() calls have finished and all the .coverage files have been written. This is quite tricky; we are running the tests in parallel, across more than one web server (--workers=2). We opted to simply wait until the number of .coverage files stabilizes. Then we combine the .coverage files and generate json and html reports:
wait_for_all_coverage_files()
{
while : ; do
echo -n .
a1="$(actual_coverage_files_count)"; sleep 0.25
a2="$(actual_coverage_files_count)"; sleep 0.25
a3="$(actual_coverage_files_count)"; sleep 0.25
a4="$(actual_coverage_files_count)"; sleep 0.25
[ "${a1}${a2}${a3}${a4}" == "${a1}${a1}${a1}${a1}" ] && break
done
echo .
}
actual_coverage_files_count()
{
find "${COV_DIR}" -maxdepth 1 -type f -name ^.coverage | wc -l | xargs
}
create_coverage_json() { ... }
create_coverage_html() { ... }
wait_for_all_coverage_files
cd “${COV_DIR}”
coverage combine --keep --quiet
create_coverage_json
create_coverage_html
When restarting the server, we want local edits to be live, so we use volume-mounts in docker-compose.yaml to “overlay” the source and test directories:
...
services:
...
volumes:
- ./source:${XY_CONTAINER_ROOT_DIR}/source:ro
- ./test:${XY_CONTAINER_ROOT_DIR}/test:ro
The top level bash script to run the tests (in the restarted container) and gather the coverage looks like this:
...
restart_server; wait_till_server_ready
run_tests_system
restart_server; wait_till_server_ready
gather_coverage
- The first
restart_servercall causes the gunicornpost_fork()handler to start coverage. - The second
restart_servercall causes the gunicornworker_exit()handler to stop and save the coverage. - Both handlers run in both restarts, but this is ok since the
post_fork()runs before theworker_exit().
In the tdd demo repo, gathering the system test coverage from a new server takes ~10 seconds; from a restarted server ~4 seconds. FTW.