

Can you imagine developing software without version control? What if I told you that we were doing exactly the same thing with DevOps?
In this article I’ll explain why developers need a database for DevOps, and make the case that it should have similar semantics to a version control system.
Can you imagine life without version control?
Life without software version control would really suck. We’d lose all the history of the changes made to our software.
We wouldn’t know who’d changed our software or why they’d made that change. Comparing any two versions of our software would be a huge pain.
We wouldn’t have an easy way to share changes either. These days we take git push for granted, but there was a time when we would have to share zip files or copy to network drives.
And how would we label these versions? We’d no doubt use some clunky method like software_project_v1.latest.final.revision3.zip.
But what about Version Control for DevOps?
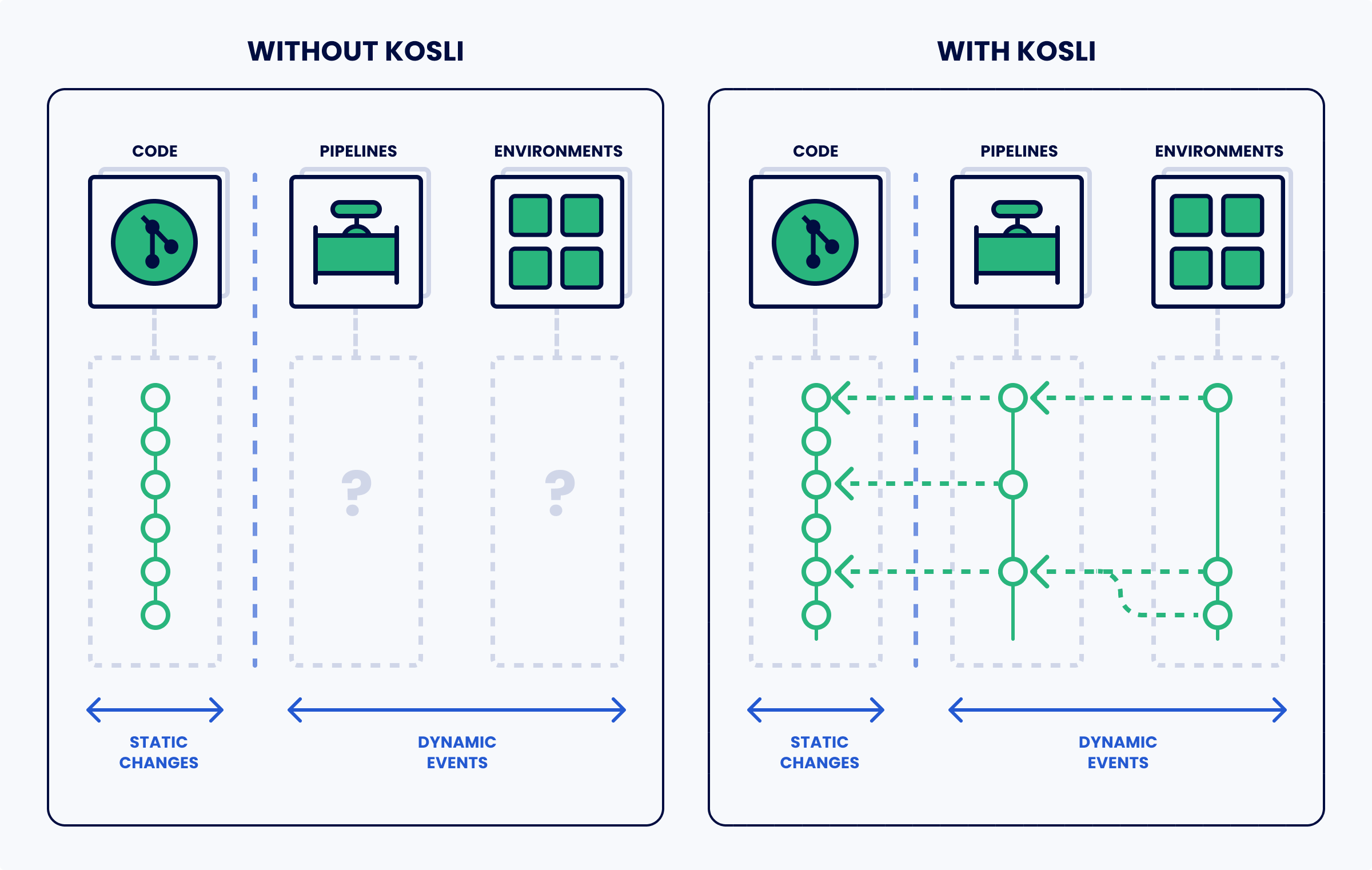
Today, all of the interesting information about our DevOps disappears instantly. Not only are we forgetting every event that happens, we have no means to navigate and understand changes as data. Our DevOps is in a state of amnesia.
Think of all the rich event data we throw away in our automation. The build binary provenance, the test results, the security scanning, and the deployment activities just vanish.
Understanding and navigating all this change requires the detective instincts of Sherlock Holmes with the technical expertise of Grace Hopper.
But what if we could preserve this data and query it?
Imagine…
A way of understanding everything in production that is as easy as git status
The ability to navigate the history of an environment that is as direct as git log.
The power to diff two environments that is as simple as git diff.
$
Now imagine the sort of higher level tooling you could build on top of this memory. You could data mine your own DevOps, gather DORA metrics, create dashboards - who knows what else?
Designing a DevOps Version Control system
Ok, but what would a history of DevOps events in a version control system look like? Maybe we can learn a thing or two from git?
Git wasn’t the first version control system, but it popularized some very important features. It introduced a snapshot-based, content-addressable storage identity, Merkel trees to ensure a secure history, and powerful collaboration modes. What if these features were available for DevOps? What would we want it to look like?
- Ideally we’d want to compare any runtime assets. We’d be able to understand all the environment changes - CDN’s, lambda functions, kubernetes containers, and configuration changes. Nothing should be out-of-band.
- Our data would be content addressable. We should be able to identify things based on secure and tamper-proof identity.
- We’d want to know that the change log is provable
- We’d want it to come with a powerful command line interface
Can we do it with git?
Git is a great version control system for source code, but its strengths in source control make for weaknesses in devops:
- It is great for recording changes in our software inputs, but not for storing outputs
- Working with additional repos in our pipelines is super clunky. In our devops pipelines and our shell we want to use a command line client.
- Git’s whole content system is based on files. This is too low level, doesn’t model the domain, and is hard to query.
- It’s distributed. This is an advantage in a source control system, where you can craft changes locally decoupled from sharing them globally. However, in a system for recording devops events we want to commit to the global stream immediately.
- It doesn’t have a developer experience and frontends to support these use cases
- It doesn’t scale to multiple teams and services
Doesn't GitOps solve this?
GitOps has been extremely important in moving from imperative to declarative definitions of deployments and infrastructure. This helps, but only for recording desired states for certain cloud-native systems. GitOps still misses how and when these desired states get applied, and their connection through the DevOps lifecycle.
Kosli is The VCS for DevOps
We didn’t set out to build a VCS for DevOps, but it’s what we’ve ended up with. It took us some time to realize that Kosli actually gives every developer the power to commit, diff, log, and status every aspect of change in their DevOps automation. The data can be gathered automatically, and be navigated from the command line, slack, and in the web browser.
How does Kosli work?
The first step is to start monitoring your production systems. This can be done with a cron job in CI, or in your favorite workload scheduler. Once this is set up, Kosli records every change to your environment.

The next step is to log important pipeline events that you would like to capture, such as builds, code reviews, test, security scans, and deployments.

What questions can you ask Kosli?
A version control system for DevOps is a powerful resource for developers, operators, auditors, and security teams who want to understand what’s happening in their pipelines and environments. With it, they can get quick and easy answers to all kinds of difficult questions
- Deployment progress: what commits are in each environment?
- Service Catalog: who owns this service?
- Time Machine: what was in production on Thursday night?
- Change Log: when did this service scale up?
- Admission Controller: is this workload approved for this environment?
- SBOM: What are the ingredients to this artifact?
- Metrics: What is the delivery lead time across pipelines?
- Compliance: What systems don’t have code review in place?
Free Tier Launching in summer
We are launching the beta of our free tier this summer. If you are interested in trying it out you can sign up for the waitlist here 👇👇
Pssst: we are hiring!




